There are many parse techniques. A compiler textbook will cover each and give the relative advantages and disadvantages of each. LALRLib uses a specific one called LALR(1). This is also what yacc and bison use, which is the main reason it was chosen. People are familiar with the issues of LALR(1) parsers and grammars are often written to be parsed by LALR(1) parsers.
General LALR(1) Parsing
The next parts of this description will explain the parts of LALR(1) processing.
LALR is a type of shift-reduce parser that uses one lookahead. It is very important that readers pay very close attention to certain words.
Nomenclature
Because sometimes words describe similar but different things, and sometimes your understanding of something depends on clearly distinguishing the differences. Specifically, and importantly, these words must be clearly understood:
Token: A token is an actual input from the scanner scanning an input character stream. A token is matched by a terminal and fed to the parser as an object that is represented by that specific terminal.
Terminal: A terminal is a symbol that is used in a rule. It represents the type of a token to be consumed in the parsing process when the containing rule is reduced. All terminals are 'symbols'.
Node: A Node is the actual result of a reduction, based on a rule. Its type is determined by the NonTerminal in the same way that a Token type is based on a Terminal.
NonTerminal: A nonterminal is a symbol that is used in a rule. It is a sort of virtual token and is the parent of zero or more symbols that results when a rule is reduced.
Tree Object: A Tree Object is a node or a token. While tokens are leaves, it is possible that nodes are not leaves at all. Nodes can be leaves (and often will be) if tokens that are consumed during reduction are no longer needed.
Symbol: A symbol is a terminal or a nonterminal. When I use the word symbol, I always mean both terminals and non-terminals.
Rule: A reduction rule is a nonterminal in the left hand side and zero or more symbols on the right hand side. For my purposes, there may be multiple unique rules with common left hand sides. Each is its own rule. The left hand side may contain on optional precedence integer.
Rule set: A set of rules that share a common left hand side.
Configuration: A rule, an indication of how much of the rule has been matched, and a lookahead set.
Configuration set: A set of configurations. A CFSM state is defined by a unique set of configurations (not taking lookaheads into account).
Rules
Rules in LALRLib are sets of symbols in the form:
LHS: RHS
Where the LHS is
NonTerminal (optional integer precedence)
and RHS is 0 or more symbols.
Examples are:
# a matches terminals B and C
a: B C
# expr has a precedence of 9
expr 9: expr * expr
# There are two rules for t. One with two nonterminals
# and one with no symbols
t: d e
t:
A rule is a way of telling the parser, that if it sees the pattern of tokens and nodes represented by the terminals and nonterminals on the right, convert them into a node of the type on the left hand side nonterminal and replace all of those symbols with the newly created node. The process of converting tree objects to a new node based on the rule is called 'reducing' or a 'reduction'. Of course it's not that simple. There are times when there is a match to the symbols, but it is not correct to do a reduction. The parser must be designed to distinguish these cases.
Check Your Understanding
Got it? Check your understanding by answering the following questions:
What is the difference between a terminal and a token?
What is the difference between a nonterminal and a node?
Which two things are subsets of symbols?
The left hand side of a rule is what?
Which things may appear on the right hand side of a rule?
To recap. A terminal is essentially the type of a token. A token is a real instance of a matched terminal's regex. A non-terminal is essentially the type of a node. A node is a real instance that is created by a rule being reduced. As tokens and node are both actual instances, they are tree objects. As terminals and non-terminals are both types used to create rule patterns, they are symbols.
Conventions
In grammars, I use some conventions. Some small sample grammars are made of just single letters. In these grammars, lower case letters represent non-terminals, and upper case letters represent terminals. In these grammars, if a $ is present, it indicates EOF.
Other grammars are meant to show something less abstract and closer to real world concepts that the reader should be familiar with. In these, the non-terminals are words and terminals tend to the actual characters matched.
Grammar
A parser parses a stream of tokens according to a grammar. The grammar is a set of rules that describe the hierarchical structure of a parse tree that is composed of these tokens and nodes that are created in the process of parsing. The grammar is composed of three basic parts:
a terminal declaration list
a nonterminal declaration list
a rule list
The terminal list is a list of all possible terminals that might appear in rules. Each terminal corresponds to a possible token-type that the scanner might deliver. A terminal may specify an associativity (L, R, or N) and precedence (integer). See the section on shift/reduce conflicts for more information on what those are and how to use them.
The nonterminal list is a list of all possible non-terminals that can appear in rules. Every non-terminal must appear on the left hand side of at least one rule and on the right hand side of at least one rule. Non-terminals correspond to a possible node type that the reducer can create.
The rule list is a list of all of the rules. Every left hand side must be a non-terminal. The right hand side is zero or more terminals and/or non-terminals. There may be multiple rules for any non-terminal on a left hand side.
An example for a small calculating language might be:
Terminals
INT /[0-9+]/
+
-
*
/
Non-terminals
exprAdd
exprMult
solution
Rules
solution: exprMult $
exprMult: INT
exprMult: exprMult * INT
exprMult: exprMult / INT
exprAdd: exprAdd + INT
exprAdd: exprAdd – INT
exprAdd: exprMult
You can see the hierarchical structure here. Take a list of tokens and see how they match up to rules.
4 + 5 * 6 $
Don't worry too much about the specifics. Just see sort of what's going on here. Each part of the token stream will match up to something in the rule set.
The process of creating the parser is moderately complex. These next sections break down the steps. With the information we have from just the grammar, we can perform the first step which is to figure out which symbols derive lambda. It's not obvious right now why this is important, but it will become clear in later steps where we have to know which symbols derive lambda.
Derives Lambda
The order of rule reduction is ultimately driven by the token stream where tokens are consumed because there is a corresponding terminal in the rule. When a rule is reduced, it consumes the tokens and nodes of the types on the right hand side to create a new node of the type on the left hand side. To "derive lambda" means that the rule can be reduced without consuming any tokens.
A rule may have zero or more symbols on its right hand side. If every rule had one or more symbols on the right hand side, things would be much easier since every reduction would involve at least one terminal or a node that has consumed a terminal. But rules with zero symbols on the right hand side make things tricky. If a rule has zero symbols, it could potentially always be reduced immediately. It can essentially be invisible with respect to the token stream. In other words, whether or not to reduce the rule doesn't, at first glance, depend on the token stream. In reality it does, but it's not immediately obvious how. This can open up the number of options for transitions. The difficulty of building a parser is due to this issue. For example, in:
f: G h J
h: K
h:
'h' has rules with zero and one symbols on the right hand side. If the grammar is matching "G K J", then the 'h' will be reduced on the token K. But when reducing "G J", the reduction of 'h' happens without consuming any tokens in the token stream. The 'h' is made some time between G and J being read.
Lambda (λ) represents the empty set of terminals. Since 'h' has a rule that can be reduced without consuming any terminals, it is said to derive lambda. It doesn’t matter that there are rules where 'h' reduces on a symbol—such as K. A rule derives lambda if there exists even one way for it be reduced without consuming tokens.
No terminals derive lambda—only a non-terminal can derive lambda. When a terminal is present in a rule, a token of that terminal is, of course, expected.
If a right hand side of a rule is composed of only nodes that derive lambda, then then that rule also derives lambda. In this example grammar:
t: X a Y $
a: b c d e
b: F
b:
c: G
c:
d: H
d:
e: J
e:
'a' derives lambda because 'b', 'c', 'd', and 'e' all derive lambda. Even with those 4 non-terminals in series, X might be followed immediately by Y.
The algorithm for figuring out which non-terminals derive lambda is simple. Start out assuming no non-terminals derive lambda. Then starting looping through all the rules.
If there is a rule that has zero symbols on the right hand side OR whose right hand side consists entirely of non-terminals that derive lambda, then that non-terminal left hand side also derives lambda.
The loop continues until it runs through once without adding any new non-terminals to the set of non-terminals that derive lambda.
foreach (terminal in grammar)
mark derives lambda as false
foreach (nonterminal in grammar)
mark derives lambda as false
bool isChanged = true
while isChanged
isChanged = false // see if the next loop causes a change
foreach rule in grammar
// only bother checking if the left hand side
// if the rule does not derive lambda
if (rule.lhs does not derive lambda)
// assume true until shown false
bool derivesLambda = true
// check the whole right hand side
foreach (symbol in rule.rhs)
if (symbol does not derive lambda)
derivesLambda = false
break out of foreach loop
// if derives lambda is still true,
// then the left hand side non-terminal
// does derive lambda
if (derivesLambda)
set rule.lhs nonterminal derives lambda to true
isChanged = true
// upon leaving the loop each non-terminal is correctly marked
We now have enough information to start constructing the Configuration Finite State Machine.
Configuration Finite State Machine (CFSM)
The configuration finite state machine is the state machine that keeps track of the parse in progress. It is a slightly unusual state machine and its use is described before an explanation of its construction.
ow to Use the CFSM
To demonstrate the CFSM, let's create a small grammar and then parse a token stream that.
Terminals
A
B
C
D
E
$ // EOF
NonTerminals
t
x
y
z
Rules
t: A x EOF
x: B y z
y: C
y:
z: D
z: E
Figure 2 A shows the CFSM for this grammar. Don't worry about where it came from, yet.
Figure 3 A: CFSM state machine for the grammar.
So, let's examine the parts of the state machine. Each rectangle is a CFSM state. The top section is the CFSM state number. The rest is the list of configurations that the state represents. In these states, the reducible configurations show a lookahead list in curly brackets. The arrows between states are transitions on terminals to be followed as tokens are consumed.
The CFSM is a state machine, but not the kind you typically find. Normally, you start in a state and then move to other states based on certain transitions. When you look at a CFSM, you see that there are many end states—i.e. states that have no transitions out. In a normal state machine, this often means that the machine has found a final state and is done. But not so with the CFSM.
In order to use the CFSM, instead of a single state integer/pointer indicating what state is active, you use 2 linked stacks. One is a shift stack. The other is a parse stack. The shift stack contains tree objects (that is, tokens and/or nodes) that partially match at least one configuration (that is, a rule with the bullet indicating how far the rule has been matched). The shift stack starts empty, and the parse stack starts with CFSM state 0.
The top of the parse stack is always the current state. The first 'current symbol' is the first token from the scanner.
If there is a transition from the current state on the current symbol, then we have a SHIFT operation. This means, the driver pushes the current symbol onto the shift stack. It pushes the transition destination CFSM state number onto the parse stack. Finally, it gets the next token from the scanner to be a new current symbol.
If there are configurations where the bullet is at the end of a rule, and the current symbol matches a lookahead token in the curly brackets, then we have a REDUCE operation. (Lookaheads are only shown for reducible states.) This means that the top of the shift stack corresponds to the symbols on the right hand side of the rule, and the reducer can turn all the right hand side tree objects corresponding to the RHS symbols into a new node that is of the type on the LHS nonterminal. We also pop off the same number of states in the parse stack. Now the reduction takes place to convert those tree objects to the LHS node and it's pushed onto the shift stack. The new state is not whatever state is at the top of the parse stack, but the transition from that state on the top symbol of the shift stack.
When a reduction is finally, possible on rule 0, this means the parse is complete. This is the ACCEPT operation. Reduce it, and return the symbol on the left hand side which contains the entire parse tree.
The final case is when there is no transition or reduction possible. This indicates a syntax ERROR.
Note that there may be states where a shift can take place and one or more reduces can take place. And there are cases where no shift can take place, but multiple reduces can. These are called shift/reduce and reduce/reduce conflicts.
An Example
Now let's use the state machine to parse the token sequence "A B D $ λ". Where λ is a pseudo-token that indicated the end of the scannable tokens.
Our parse stack has 0. Our shift stack is empty. And the current symbol is the first token from the token sequence which is 'A'. Let's review our stacks and current symbol.
Parse stack: 0
Shift stack:
Current symbol: A
The current state is found by peeking at the top of the parse stack. We see a transition from CFSM state 0 on 'A' to state 1. This is a SHIFT operation. In a shift, we push the new state onto the parse stack and push the current symbol on the shift stack.
Notice what this means for the configurations. By shifting on 'A', we go from a state where the • is immediately before the 'A' in a rule to one where the • has jumped to the other side of the 'A', i.e. from "t: • A x $" to "t: A • x $". The • being just to the right of the 'A' means that there is an 'A' at the top of the shift stack.
Finally, the current symbol has been shifted onto the shift stack, so we need to get the next one from the token stream. That is 'B'.
This is the basic SHIFT operation. Every shift works just like this.
Let's review our stacks and current symbol.
Parse stack: 0 1
Shift stack: A
Current symbol: B
The symbol right after the • is 'x'. We need to shift an 'x' to get to CFSM state 3. But we don't have an 'x'. The current symbol is a 'B'. But, notice, that the configuration "t: A • x $" has a closure. That is, another configuration that's going to help us get our 'x'. Note that CFSM state 1 also has "x: • B y z".
Since our current symbol is a 'B', we shift again to CFSM state 2. We push it onto the parse stack and push the 'B' onto the shift stack. The next current symbol comes from the token sequence and is 'D'.
Let's review our stacks and current symbol.
Parse stack: 0 1 2
Shift stack: A B
Current symbol: D
Now we have our first REDUCE operation.
There is no transition on CFSM state 2 on 'D', but 'D' is in the lookahead sets of a reducible configuration. The lookaheads only are used in decisions of configurations that end in the •. There is one configuration like that: "y: • { D, E }". The fact that there is a reducible configuration with the current symbol in its lookahead list means we do that reduction.
A reduction has a few more steps than a shift. First count the number of symbols in the right hand side. In this case, there are zero. We pop zero states off the parse stack. And pop zero symbols off the shift stack. Now we create a new node 'y' passing the reducer the symbols popped off the shift stack (none in this case). Next, we push the 'y' onto the shift stack. Then we look at what CFSM state 'y' transitions to from the CFSM state at the top of the parse stack. In this case, because zero states were popped off, it's still state 2. CFSM state 2 transitions to CFSM state 5 on 'y'. So we push 5 onto the parse stack.
Let's review our stacks and current symbol.
Parse stack: 0 1 2 5
Shift stack: A B y
Current symbol: D
Now, the current CFSM state is 5 (because it is the top of the parse stack) and the current symbol is 'D'. Again there is a shift to CFSM state 7. So we push 7 onto the parse stack, push 'D' onto the shift stack, and get the next symbol from the token stream: '$'.
Let's review our stacks and current symbol.
Parse stack: 0 1 2 5 7
Shift stack: A B y D
Current symbol: $
CFSM state 7 is pretty simple. It is just a "z: D • { $ }". Since the current symbol is '$' that means we do follow that reduction. This time there will be popping since there is one symbol on the right hand side.
So we pop one off the parse stack and throw it away. We pop 'D' off the shift stack and give it to whatever is going to reduce 'D' to a 'z'. We get the 'z' and push it onto the shift stack.
The top CFSM state is no longer 7, but is now 5 because the 7 got popped. So, there better be a transition in CFSM state 5 on 'z'. And, indeed, there is. It goes to CFSM state 9. So we push 9 onto the parse stack.
Let's review our stacks and current symbol.
Parse stack: 0 1 2 5 9
Shift stack: A B y z
Current symbol: $
The next operation will be a reduce. The readers are urged to convince themselves that the stacks and current symbols will look like this:
Parse stack: 0 1 3
Shift stack: A x
Current symbol: $
Next, a shift. When the scanner runs out of tokens, it must deliver a 'λ' token. Again, the stacks and current symbol will look like this:
Parse stack: 0 1 3 6
Shift stack: A x $
Current symbol: λ
We are getting close. CFSM state 6 is the accept state. So the operation is an ACCEPT. It works just like the REDUCE up until the stack pushes which are not necessary because we are done. Once "t: A x $ •" has been reduced, we have the goal symbol 't' and we are done. The node 't' contains the entire parse tree.
No error was shown in the example. An error is just when there are neither a valid reduce, shift, or accept. In this parse scheme, the parse is stopped. Advanced usages can recover from errors, but this grammar and parser cannot.
CFSM Construction
Now that a CFSM has been demonstrated in operation, we can start to see how they are constructed.
First, let's review the difference between a rule and a configuration as the terms are used here. A rule is a left hand non-terminal and zero or more right hand symbols (i.e. terminals and non-terminals). A configuration is 1) a rule, 2) an indication of how much of the rule has been matched, and 3) a set of lookaheads which are all the possible terminals that might be seen by the configuration if the configuration is being followed. The location of how much of the rule has been matched so far is done with a thick bullet. The thick bullet may appear at the beginning, the end, or between any two symbols.
Rule Zero
As stated earlier, there is one rule that must reduce to the goal symbol and must end in EOF ($). CFSM 0, the first state is the state which has the configuration with that rule and the bullet at the beginning of the rule. Once CFSM0 exists, transitions to other states are used to construct the entire state machine until no more transitions exist.
For example, recall the grammar just demonstrated:
t: A x EOF
x: B y z
y: C
y:
z: D
z: E
The configuration that will be found in CFSM 0 is: "t: • A x $ {λ}". This configuration is the first rule, the bullet indicating how much has been matched (none of it). Though this rule has a lookahead set of {λ}, let's ignore lookaheads for this explanations. In fact, the creation of lookaheads is done in the next step, so even though lookaheads are normally part of a fully formed configuration, these configurations are not yet fully formed.
Closure
Recall above, that CFSM state 1 had not only "t: A • x $" but also "x: • B y z". Where did that come from? It came from the process called closure. In order to get to "t: A x • $" there has to an 'x' to push onto the shift stack. But 'x' is a non-terminal and won't appear in the token stream—it can only be created at the result of a reduction. So at some point, 'x' has to be created and we have to get back to this state so we can advance the •.
This section explains closure.
To close a configuration or set of configurations, add all rules that have a left hand side that is the same as any non-terminal immediately following a bullet. So in the grammar above, the rule "x: B y z" closes "t: A • x $" because the 'x' is a nonterminal right after the bullet. The configuration "t: • A x $" does not require any closures because 'A' is a terminal. The closures are always configurations with the bullet at the beginning, i.e. nothing is matched yet. Added rules may require their own closures, as well. Keep adding them in a cascading manner until every single configuration with a non-terminal to the immediate right of a bullet has a corresponding set of all rules with that non terminal on the left had side.
Transitions
The next step is to find the transitions. The transitions are all symbols that immediately follow a bullet. In the case of CFSM 1, there are transitions on the non-terminal 'y' and the terminal 'B'. The transitions are made by advancing the bullet over the symbol to get a new configuration that will be the foundation of a new or existing CFSM state. In the case of 'y', the new configuration is made by advancing the bullet, so that it looks like "x: B • y z". This will be the foundation of a new state CFSM 2. Since 'z' is a non-terminal, the two rules with z on the left hand side will be added with the • at the beginning. So the CFSM consists of:
x: B y • z
z: D •
z: E •
This process is repeated on each new CFSM state. Again the process is:
1. For each symbol to the right of a bullet, create a new configuration with the bullet advanced one symbol to the right
2. Close the new configuration. If there is already an existing CFSM state with those same configurations, then use that state to transition to, otherwise create a new CFSM state and set the transition to go there.
The compete CFSM for the grammar (without lookaheads) above is shown in Figure 2 B.
Figure 3 B: The CFSM state machine after construction without lookaheads.
This is the algorithm for generating the CFSM machine:
config0 = new config (ruleArray[0], 0)
configSet = closure(config0)
cfsm = createOrGetCFSMstate(configSet)
index = 0
while (index < CFSMlist.length)
foreach (symbol in symbolArray)
transConfigSet = new configSet
foreach (config in configSet)
if (config.next == symbol)
transConfigSet.add(config)
if (transConfigSet.length > 0)
configSetTo = closure(transConfigSet)
cfsmTo = createOrGetCFSMstate(configSet)
cfsm.transitions[symbol] = cfsmTo
where the algorithm for createOrGetCFSMstate is:
key = createKeyFromConfigSet(configSet)
if (cfsmDictionary[key] == null)
cfsm = new cfsm(configSet)
cfsmDictionary[key] = cfsm
cfsmList.add(cfsm)
Once the CFSM is complete, it is time to create the lookaheads.
Lookahead Generation
Lookaheads are all possible terminals (i.e. token types) which can legally appear immediately following the end of a rule reduction. There are lookaheads for configurations that don't yet have the bullet at the end, but these lookaheads aren't used in these configurations to make reduction decisions since only a configuration with a bullet at the end can be reduced. These are simply maintained for lookahead propagation.
The lookaheads are used to help the parser generator decide which configuration to reduce when there are multiple configurations that might be reduced or if there rules that can be reduced, but also possible transitions to other states. This will be explained later, but first I will explain the process of lookahead generation.
The method used by LALRLib is lookahead propagation. This consists of these steps:
1. determine propagation links
2. seed the initial lookaheads
3. propagate the lookaheads along the links
These next sections explain each step in turn.
Lookahead Propagation Links
A propagation link is a link from a configuration to another configuration. The link is created if the presence of lookaheads in the source implies that the lookaheads also appear in the destination. In LALR(1) parsers, there are two conditions that create this situation. Shifts and closures.
Links From Shifts
Recall that a shift is when the bullet goes over the next symbol in a rule and goes to a state that is based on that new configuration. For example, in "x: B • y z" in state 2 shifts on 'y' and goes to state 5 which is founded on "x: B y • z". A lookahead is a terminal that might be seen after a rule reduces. Now, you can't reduce a rule whose • is not at the end of the configuration, but if we determine that a lookahead is found after an upstream configuration, it follows that it will be a lookahead all the way downstream to the reducible configuration.
The algorithm for creating links from shifts is to just go through every configuration of every CFSM state and create a link from every configuration whose • is not at the end to the configuration in the downstream state. So there will be a propagation link from "x: B • y z" in state 2 to "x: B y • z" in state 5. After all, if a token will be seen after "x: B • y z" is reduced, it will be seen after "x: B y • z" is reduced. And "x: B y z •", too, of course.
Algorithm for determining shift based propagation links:
foreach CFSMstate in CFSMstateMachine
foreach config in CFSMstate
// get the symbol after the • [(null) if • is at the end]
symbol = config.next
if (symbol != null)
// get destination state
destCFSM = CFSMstate.getTransitionOn(symbol)
// get destination configuration
config.addPropLink(destCFSM, config.shift)
// The shift based propagation links are now set up
Links From Closures
The other source of propagation links is closures. While every shift results in a propagate link, not every closure results in a propagation link. Recall what a closure is. A closure is where a configuration with the • before a non-terminal gets a cascading set configurations of all the rules where the left hand side is that non-terminal to the right of the •. For example, in "x: B • y z" in state 2, the 'y' is a non-terminal to the immediate right of the •. So, all rules with 'y' on the left hand side are turned into configurations with the • at the beginning and added to the CFSM state. This means, "y: • C" and "y: •" are added as closures to "x: B • y z".
In this particular grammar, 'z' does not derive lambda, so there is no propagation link. But consider this grammar:
t: a X
a: b c
b: P
b:
c: Q
c:
A CFSM with "a: • b c" will get, as closures, "b: • P" and "b: •". Since 'b' and 'c' both derive lambda, any lookahead which is visible after "a: b c •" reduces will also be valid lookaheads as "b: P •" or "b: •" reduces. In other words, 'X' will be a lookahead of 'a', so it will also a possible lookahead of "b: P •" and "b: •". Observant reader might also notice that 'Q' is a potential lookahead of those two. That is true, and will be covered evaluating "a: b • c". For now, it is just important to note how closures result in propagation links.
A propagation link needs to be set up from a configuration to any closure if all symbols to the right of the non-terminal immediately right of the • all derive lambda.
The algorithm follows:
foreach CFSMstate in CFSMstateMachine
foreach config in CFSMstate
// get the symbol right of the •
next = config.next
if (next is not null and next is a non-terminal)
// symbol is a non-terminal. If the rest to its
// right all derive lambda, we need a propagate link
foreach symbol right of next
if symbol does not derive lambda
break out of the foreach config loop
// Got here because the condition for a link were met
foreach config2 in CFSMstate
if config.rule.lhs = next && config.location == 0
// we have found a closure
// create the link
config.addPropLink(CFSMstate, config2)
// now all the closure propagation links are set up
That's complicated! Let's create an example. This example will demonstrate the following:
1) a propagate link across a shift
2) a propagate link across a closure
3) a closure that does not have a propagate link
Consider this grammar:
a: b C $
b: d
d: e f
e: G
e:
f: H
f:
It's not a useful grammar. It parses only the following strings of tokens: GC, HC, GHC, or C. The following configuration sets are numbered to identify the specific configuration in a set. Here is a subset of a CFSM with its configurations.
CFSM 0
1) a: • b C $
2) b: • d
3) d: • e f
4) e: • G
5) e: •
6) f: • H
7) f: •
CFSM 1
1) a: b • C $
CFMS 4
1) d: e • f
2) f: • H
3) f: •
There is a propagate link across the shift on 'b' from CFSM 0 to CFSM 1. Why? Because a Lookahead is a valid terminal that may appear when the configuration is reduced. The terminal that will appear after "a: • b C $" is the pseudo-token λ.
Once the lookahead propagation links are created, they should look like the following where the pairs in square brackets show the CFSM state ID and configuration ID. There would be additional propagate links not shown here for shifts out of these 3 states. Only the propagate links that start and end in these three states are shown.
CFSM 0
0) a: • b C $ [1,0] [0,1]
1) b: • d [0,2]
2) d: • e f [4,0] [0,3] [0,4]
3) e: • G
4) e: •
5) f: • H
6) f: •
CFSM 1
0) a: b • C $
CFMS 4
0) d: e • f [4,2] [4,1]
1) f: • H
2) f: •
Calculate First Set
Before going into the initial lookaheads, it is useful explain the "first set" and how to construct it. A first set is the set of all terminals that can be found immediately after a non-terminal in a rule. The first set is not a property of the non-terminal itself but the non-terminal at its specific location in a rule. The same non-terminal in a different configuration may have a different first set. For the rule where the non-terminal appears on the right hand side, look to the right of the non-terminal. If it is immediately followed by a terminal, that terminal is added to the first set. If it is immediately followed by a non-terminal, that non-terminal's first set is added (except lambda). If the non-terminal derived lambda, that is, may get reduced without consuming tokens, then the same operation is done on the next symbol. This continues until a either a terminal or a non-terminal that doesn't derive lambda is encountered. If there are no symbols to the right or all symbols to right are non-terminals that derive lambda, then lambda is added to the first set.
// Find the first set for the nth symbol in the right hand side of a rule
// start a collection of terminals
firstSet = new empty collection
bool removeLambda = false
for (i = n+1 to rule.rhs.length)
// if the symbol at [i] is a terminal, add it to the
// first set and stop
if (rule.rhs[i] is a terminal)
firstSet.add(rule.rhs[i] as terminal)
removeLambda = true
break out of the for loop
else // symbol is non terminal
firstSet.Add( recursive call with first set of i+1 in rule)
// keep going if the non-terminal derives lambda
if (rule[i] does not derive lambda)
removeLambda = true
break out of the for loop
// if the loop was broken out, remove lambda.
// if the loop continued to the end, add lambda
if (removeLambda)
firstSet.remove(λ)
else
firstSet.add(λ)
//firstSet now contains the list of all terminals
Seed the Initial Lookaheads
The configuration for Rule 0 which reduces the goal symbol (i.e. the root of the final parse tree) has lambda as the lookahead. Lookaheads are also determined by looking at the "first set" of all the non-terminals.
First, the λ symbol is the only valid lookahead for Rule 0 which contains the goal object and EOF. So it is preloaded with that. So, a: • b C $ gets a: • b C $ [λ]. The first configuration is added to the propagate queue.
Recall that a lookahead is a terminal that can be seen immediately after the reduction of a rule. From each configuration we can see what terminals might immediately follow any non-terminal.
Any non-terminal with a terminal to its immediate right will have that terminal as a lookahead. So the closure of "a: • b C $" which is "b: • d" will get C as its lookahead seed (eventually to be propagated to "b: d •", because when the "b: d •" is reduced, C must be the next token in the token stream.
The symbols to the right of the • don't have to be terminals. In fact, the first set of the non-terminal will be the initial lookahead set. In other words, the first set just described in the last section.
Here is the algorithm for generating the lookahead seeds.
foreach CFSMstate in CFSMstateMachine
foreach config in CFSMstate.configurations
// only need to get lookaheads for
if (config.next is non terminal)
// get first set for this non-terminal
firstSet = firstset(
config.rule,
config.next.index+1)
// now seed the configurations whose
// lhs is that non-terminal
foreach config2 in CFSMstate.configurations
if config2.rule.lhs == config.next
config2. lookaheads.mergewith(
firstset
)
propagateQueue.enqueue (config2)
//
Lookahead Propagation
Once the links are created, the initial lookahead seeds are determined, they are propagated. The method used by LALRLib to keep track of configurations that have new lookaheads in a queue.
A configuration is dequeued. Its propagate links are walked and all lookaheads are propagated. If there is a change in the destination configuration, it is added to the queue. This is continued until the queue is empty.
The algorithm follows:
while propagateQueue is not empty
fromConfig = propagateQueue.dequeue()
foreach (toConfig in fromConfig.propLinks)
toConfig.lookaheads.mergein(fromConfig.lookaheads)
if (toConfig lookahead count increased)
propagateQueue.enqueue(fromConfig)
// All lookaheads are now propagated
The CFSM states now have the proper lookaheads.
Parse Table Generation
Once the CFSM is complete, it can be made into a table. Or more accurately, maybe it can be made into a table. The table is two dimensional and has the CFSM states on one axis and the set of all symbols (terminals and non-terminals) on the other. It contains cells where each cell of the table contains an action and CFSM state ID or rule ID.
Recall that when using a CFSM, there are four possible actions. We can shift, reduce, accept, or fail on a syntax error.
A shift happens when there is a transition on a symbol. So for all symbols which have transitions out of a CFSM state, the action on that CFSM state with that symbol might be SHIFT and the new CFSM state ID is stored.
A reduce happens when there is a configuration whose bullet is at the end of the rule and the current terminal is contained in the lookahead list. If there is such a configuration, the CFSM action might be REDUCE and the rule ID is stored.
An ACCEPT is just the special case of the reduction of Rule 0. This indicates the parse is complete. There will only be one object on the shift stack and that object is the goal object with the entire parse tree.
Finally, if there is no shift, reduce, or accept, the CFSM action is to indicate a syntax error.
But, the CFSM is not necessarily free of ambiguities.
Consider a CFSM state. Look at the Lookahead lists of all configurations ready to be reduced and all possible terminals for which there is a transition. Does any single terminal appear in more than of these places? If yes, there is ambiguity.
There may more than one be reducible configuration with overlapping terminals in the lookahead list. Or there may reducible configurations whose lookahead list overlaps with terminals for which there is a shift to another state.
The next section will discuss these conflicts.
Conflicts
Sometimes, when seeing what can shift and what can reduce, there are more than one option for a CFSM state at a transition. These fall into the shift/reduce and reduce/reduce categories. These conflicts are the bane of LALR parser usage and many hours of computer science have gone into studying them. So the treatment here will highlight some common issues and their solutions. But note that it is possible to go much deeper than this explanation.
There are 2 classic shift/reduce conflicts. The well-known operator precedence and associativity conflicts and the if/if/else conflict. The next two sections discuss these classic problems. Reduce/reduce conflicts generally, apparently, mean the grammar has issues that need resolving.
Where "+" and "-" have precedences of 8 and "*" and "/" have precedences of 9.
We want to be able to parse the following lines:
1 + 2 * 3
3 - 2 - 1
Say we'd like to ensure that these are interpret as "1 + (2 * 3)" and "(3 – 2) – 1".
The way "1 + (2 * 3)" is resolved is through precedence. The way "(3 – 2) – 1" is resolved through associativity.
Precedence
It is possible to apply a precedence to a terminal and to rules. If they have precedence, and there is a shift/reduce or reduce/reduce conflict, the precedence is used to resolve it.
So, consider what happens when "1" (actually an expr node reduced from NUMBER), "+", and "2" (actually an expr node reduced from NUMBER) have been shifted onto the shift stack. The parser wants to act on the "*". There is a reduce on "expr 8: expr + expr •" available as well as a shift on "*". It happens that these have priorities. The rule ready to be reduced has a precedence of 8. The "*" operator has a precedence of 9. When the token terminal precedence is higher, it wins and there is a shift. If the reduce rule has the higher priority, it wins and the reduction occurs. So there will be a shift. The 2 * 3 will be reduced while the 1 + is on the shift stack. Then the 1, +, and (2*3) will be reduced. The result will be 1 + (2 * 3).
Associativity
Now consider what happens in "3 – 2 – 1". Again the shift stack contains "3" as an expr reduced from NUMBER, a "-", a "2" reduced from number, and the parser is acting on the second "-" operator. Here, the precedence for both is 8. So there is a tie. Associativity is the way to resolve a shift/reduce conflict when there is a tie after looking at precedences.
If the parser generator shifts, then it will reduce "2-1" and then reduce "3 - (2-1)". If the parser generator reduces immediately, "3-2" will be created and at the end the effect will be "(3-2)-1".
So, by shifting, the result is right-associativity of the - operator. By reducing, the result is left associativity of the - operator. If we say no associativity, the parser generator complains and fails. This is useful for identifying cases where you aren't expecting ties.
YACC, uses %left, %right, and %nonassoc to specify these. LALRLib uses L (left), R (right), and N (none). It would also be possible to specify the actual operation, i.e. shift or reduce rather than the result. But, I take it to be customary to use the result, so I followed that convention.
if if else
Consider this grammar segment
…
stmt: if cond stmt
stmt: if cond statement else stmt
…
This part will parse this snippet:
if cond0 if cond1 stmt2 else stmt3
When the parser generator gets to "stmt: if cond stmt •" and "stmt: if cond stmt • else stmt" with the current symbol "else", the parser generator can choose to shift or reduce. The result may be "if cond0 { if cond1 { stmt2} else {stmt3} }" or "if cond0 { if cond1 { stmt2} } else {stmt3}". It makes a big difference. Typically, you want the else to go with the closest previous if. So you want to shift.
The key to this is to create a priority on the else terminal that is higher than on the rule. This forces a shift. The else will then reduce with the second if. It is the common way to resolve the conflict.
Let's rewrite the relevant parts.
else N2
…
stmt 1: if cond stmt
stmt: if cond statement else stmt
…
The default precedence for everything is 0. So the else token rule will win. It will shift
Reduce/Reduce Conflicts
There don't seem to be any classic reduce/reduce conflicts. If you get a reduce/reduce conflict, it means you have to improve your grammar.
Parse Table Driving
The parse table driver uses two stacks, 1) a shift stack and 2) a parse stack. It also has a current symbol that is not actually on a stack. To start, CFSM state 0 is pushed onto the parse stack. The state at the top of the parse stack is always the current state. Current is set by pulling the first token from the token stream.
The parser driver is now initialized.
Current symbol and the current state are indices into the parse table. It has 4 actions: shift, reduce, accept, and error.
If the action is shift, there is a new state ID in the cell as well. It is pushed onto the parse stack. The current symbol is pushed onto the shift stack and a new current symbol is pulled from the token stream.
If the action is reduce, there is a rule ID in the cell as well. The number of items in the RHS of the rule are popped off the shift stack, the rule is reduced which returns a new node which is the current symbol. Then the number of items pulled off the shift stack are pulled off the parse stack and thrown away.
If the action is accept, a reduce operation is done as described above, but the parse driver ends with a valid program.
Finally, if the action is error, a syntax error has occurred and the parser driver must give up.
The algorithm for the driver is:
parseStack = new stack
shiftStack = new stack
parseStack.Push(0)
current = tokenStream.next
loop
CFSMid = parseStack.Peek()
switch (parseTable[CFSMid, current.Id].action)
case SHIFT
parseStack.push (CFSMid)
shiftStack.Push (current)
current = tokenStream.next
case REDUCE
rule = ruleArray[parseTable[CFSMid, current.Id].id]
symbols = shiftStack.pop (rule.rhs.length)
parseStack.pop (rule.rhs.length)
lhs = reduce (rule, symbols)
shiftStack.push (lhs)
// shift to the state based on the lhs
goto = parseTable[CFSMid, lhs.id].id
parseStack.push (goto)
case ACCEPT
rule = ruleArray[parseTable[CFSMid, current.Id].id]
symbols = shiftStack.pop (rule.rhs.length)
parseStack.pop (rule.rhs.length)
goal = reduce (rule, symbols)
return goal
case ERROR
throw exception
Specific Issues
C# is not LALR(1)
My goal was to parse C#. However, C# is not parsable with an LALR(1) parser using a context free grammar.
But, there are solutions. One is to add context. This would mean the parser would know every identifier and what it is. Coding this would not be easy. And I would be precluded from parsing snippets of code. So I decided to see if there was another way. As I was developing the grammar, I ran into these problems:
1) "<" and ">" can be operators or they can be part of generic types
2) ">>" can be an operator or end of nested generic types
3) "[" and "]" have similar issue to "<" and ">" as the grammar had trouble dealing with the fact that sometime they are part of an array type and other times they index the array in an expression
4) Predicates () => () or maybe not. The predicate grammar is designed to be fairly minimal. It is also tricky to parse
So, the idea of the token stream converter was born. (Actually, I suspect it has been independently invented several times before). A converter sits between the scanner and the parser and manipulates the token stream.
In the beginning of this paper I wrote:
Letter/numbers/symbols/etc SCANNER tokens PARSER parse tree
But, a more accurate representation now is:
Letter/numbers/symbols/etc SCANNER tokens CONVERTER tokens PARSER parse tree
The converter part is cascaded converters, each of which handles different issues. There is some order dependency. The converters have two methods of operation. One is token substitution where tokens are substituted for other tokens. The other is delimiting where delimiter pseudo-tokens are inserted into the stream to mark the beginning and end of a grouping.
Each converter looks for specific tokens that signal the possible start of a pattern. Tokens are then pulled in and queued until it is established if there is a pattern or not. If the pattern is found, the queue of tokens is manipulated. If not, the converter just serves up its queued tokens before pulling from the stream again.
PseudoToken Substitution
LALRLib has 2 cases of token substitution. The angle brackets, "<" and ">" and the square brackets "[" and "]".
Once the left angle bracket is seen the converter starts pulling in tokens and matching patterns until it determines what the left angle bracket is. If it is followed only by identifiers, dots, more left angle brackets, matching right angle brackets, square brackets, and commas, then when the matching right angle bracket is found, it is assumed that all "<" can be replaced by "" is replaced by "g>" which is a pseudo-token representing the generic type right angle bracket. Further, ">>" is replaced by two "g>" tokens.
Square brackets are a little easier. The only thing allowed inside [] when they represent an array type is the comma. In any other case, they represent the actual indexing. So when they are part of an array type, they are replaced by "[d" and "d]" which are the pseudo-tokens representing array types.
Pattern Delimiting
The converters also handle delimiters of types and predicates. If a string of tokens can be unambiguously identified as a type, "type-start" and "type-end" pseudo-tokens are inserted into the stream. This happens when a native type is seen or identifiers are followed by "" follows the matching ")" or appears sooner. A "pred-start" pseudo-token is inserted before the "(" if there is a ")" before the "=>" otherwise after the last "(" before the "=>". The "pred-end" pseudo-token is placed after the ….
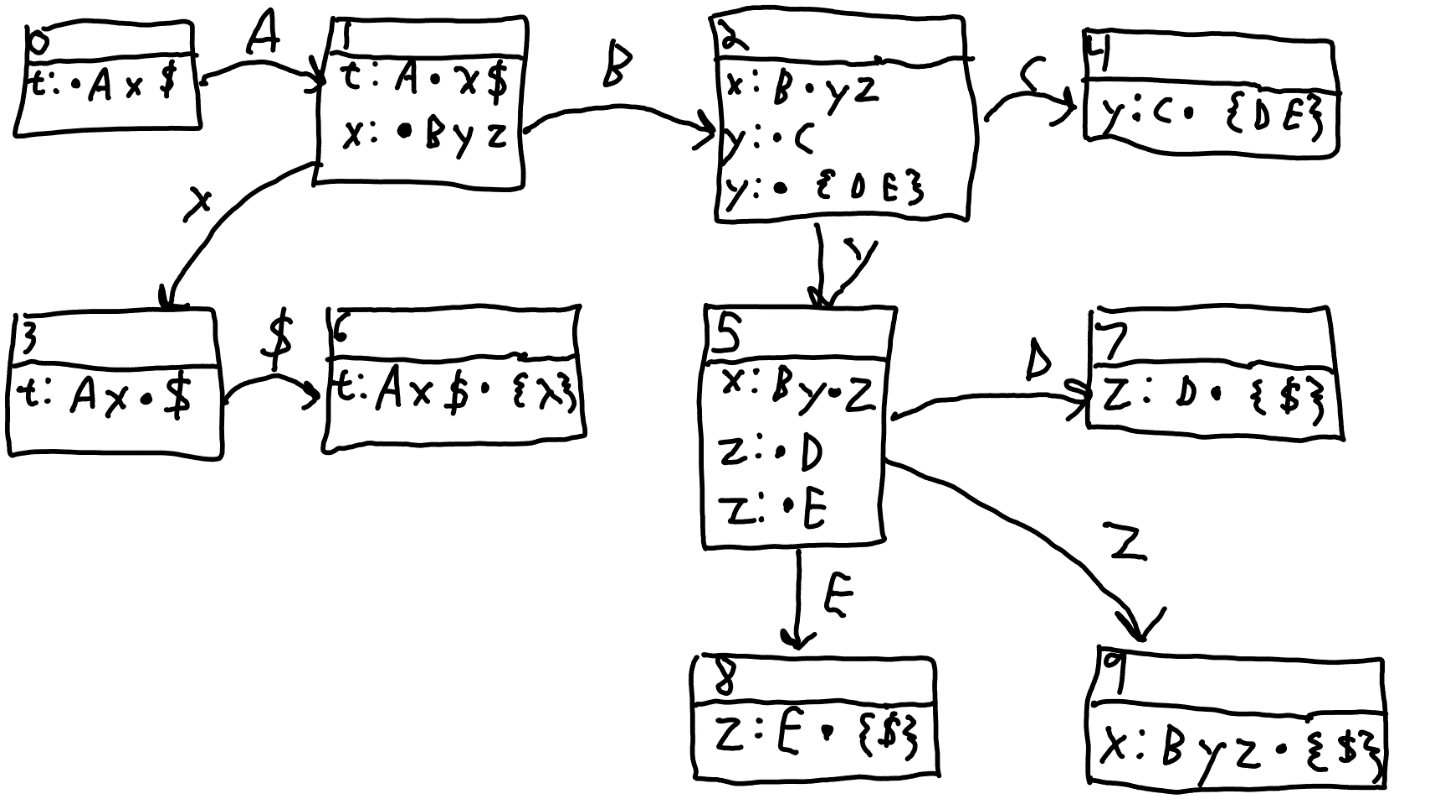 Figure 2 A shows the CFSM for this grammar. Don't worry about where it came from, yet.
Figure 2 A shows the CFSM for this grammar. Don't worry about where it came from, yet.
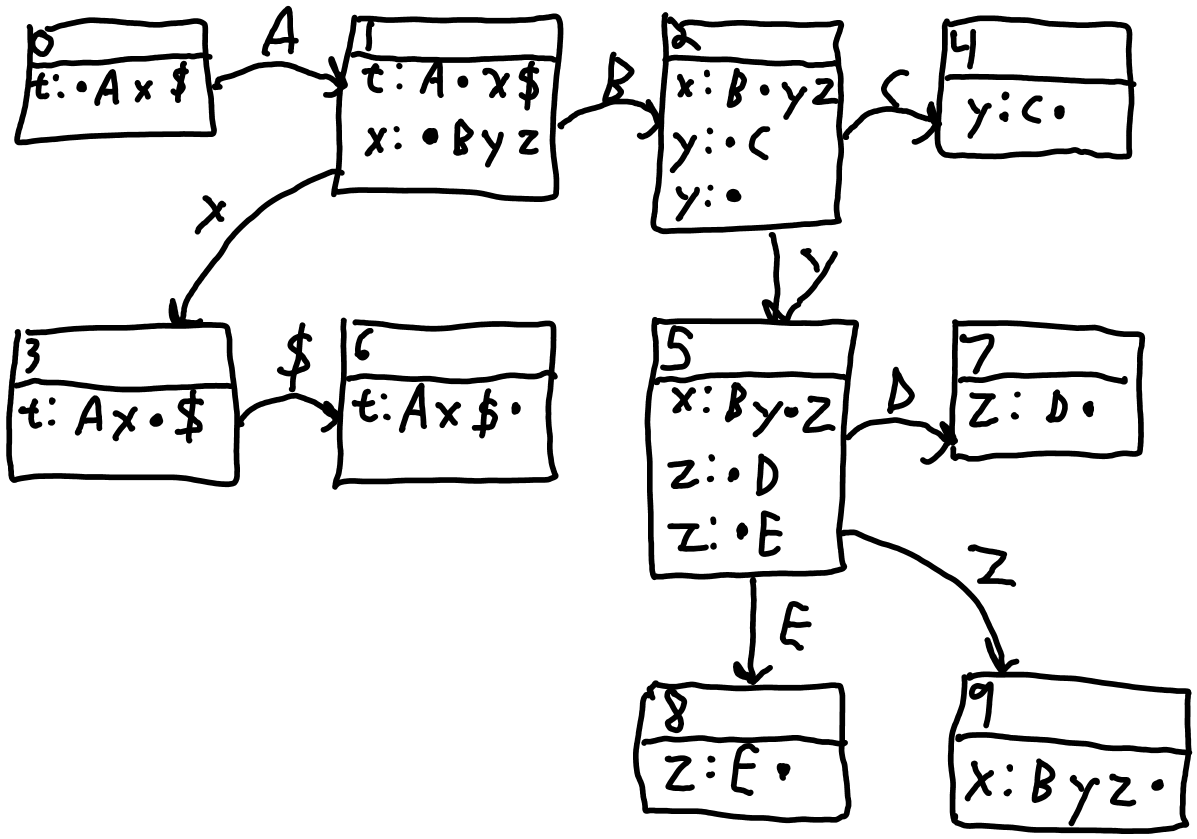 Figure 3 A: CFSM state machine for the grammar.
So, let's examine the parts of the state machine. Each rectangle is a CFSM state. The top section is the CFSM state number. The rest is the list of configurations that the state represents. In these states, the reducible configurations show a lookahead list in curly brackets. The arrows between states are transitions on terminals to be followed as tokens are consumed.
The CFSM is a state machine, but not the kind you typically find. Normally, you start in a state and then move to other states based on certain transitions. When you look at a CFSM, you see that there are many end states—i.e. states that have no transitions out. In a normal state machine, this often means that the machine has found a final state and is done. But not so with the CFSM.
In order to use the CFSM, instead of a single state integer/pointer indicating what state is active, you use 2 linked stacks. One is a shift stack. The other is a parse stack. The shift stack contains tree objects (that is, tokens and/or nodes) that partially match at least one configuration (that is, a rule with the bullet indicating how far the rule has been matched). The shift stack starts empty, and the parse stack starts with CFSM state 0.
The top of the parse stack is always the current state. The first 'current symbol' is the first token from the scanner.
If there is a transition from the current state on the current symbol, then we have a SHIFT operation. This means, the driver pushes the current symbol onto the shift stack. It pushes the transition destination CFSM state number onto the parse stack. Finally, it gets the next token from the scanner to be a new current symbol.
If there are configurations where the bullet is at the end of a rule, and the current symbol matches a lookahead token in the curly brackets, then we have a REDUCE operation. (Lookaheads are only shown for reducible states.) This means that the top of the shift stack corresponds to the symbols on the right hand side of the rule, and the reducer can turn all the right hand side tree objects corresponding to the RHS symbols into a new node that is of the type on the LHS nonterminal. We also pop off the same number of states in the parse stack. Now the reduction takes place to convert those tree objects to the LHS node and it's pushed onto the shift stack. The new state is not whatever state is at the top of the parse stack, but the transition from that state on the top symbol of the shift stack.
When a reduction is finally, possible on rule 0, this means the parse is complete. This is the ACCEPT operation. Reduce it, and return the symbol on the left hand side which contains the entire parse tree.
The final case is when there is no transition or reduction possible. This indicates a syntax ERROR.
Note that there may be states where a shift can take place and one or more reduces can take place. And there are cases where no shift can take place, but multiple reduces can. These are called shift/reduce and reduce/reduce conflicts.
Figure 3 A: CFSM state machine for the grammar.
So, let's examine the parts of the state machine. Each rectangle is a CFSM state. The top section is the CFSM state number. The rest is the list of configurations that the state represents. In these states, the reducible configurations show a lookahead list in curly brackets. The arrows between states are transitions on terminals to be followed as tokens are consumed.
The CFSM is a state machine, but not the kind you typically find. Normally, you start in a state and then move to other states based on certain transitions. When you look at a CFSM, you see that there are many end states—i.e. states that have no transitions out. In a normal state machine, this often means that the machine has found a final state and is done. But not so with the CFSM.
In order to use the CFSM, instead of a single state integer/pointer indicating what state is active, you use 2 linked stacks. One is a shift stack. The other is a parse stack. The shift stack contains tree objects (that is, tokens and/or nodes) that partially match at least one configuration (that is, a rule with the bullet indicating how far the rule has been matched). The shift stack starts empty, and the parse stack starts with CFSM state 0.
The top of the parse stack is always the current state. The first 'current symbol' is the first token from the scanner.
If there is a transition from the current state on the current symbol, then we have a SHIFT operation. This means, the driver pushes the current symbol onto the shift stack. It pushes the transition destination CFSM state number onto the parse stack. Finally, it gets the next token from the scanner to be a new current symbol.
If there are configurations where the bullet is at the end of a rule, and the current symbol matches a lookahead token in the curly brackets, then we have a REDUCE operation. (Lookaheads are only shown for reducible states.) This means that the top of the shift stack corresponds to the symbols on the right hand side of the rule, and the reducer can turn all the right hand side tree objects corresponding to the RHS symbols into a new node that is of the type on the LHS nonterminal. We also pop off the same number of states in the parse stack. Now the reduction takes place to convert those tree objects to the LHS node and it's pushed onto the shift stack. The new state is not whatever state is at the top of the parse stack, but the transition from that state on the top symbol of the shift stack.
When a reduction is finally, possible on rule 0, this means the parse is complete. This is the ACCEPT operation. Reduce it, and return the symbol on the left hand side which contains the entire parse tree.
The final case is when there is no transition or reduction possible. This indicates a syntax ERROR.
Note that there may be states where a shift can take place and one or more reduces can take place. And there are cases where no shift can take place, but multiple reduces can. These are called shift/reduce and reduce/reduce conflicts.